
Writing clean code can be challenging: Libraries, frameworks, and APIs are temporary and become obsolete quickly. But mathematical concepts and paradigms are lasting; they require years of academic research and may even outlast us.
This isn’t a tutorial to show you how to do X with Library Y. Instead, we focus on the enduring principles behind functional and reactive programming so you can build future-proof and reliable Android architecture, and scale and adapt to changes without compromising efficiency.
This article lays the foundations, and in Part 2, we will dive into an implementation of functional reactive programming (FRP), which combines both functional and reactive programming.
This article is written with Android developers in mind, but the concepts are relevant and beneficial to any developer with experience in general programming languages.
Functional Programming 101
Functional programming (FP) is a pattern in which you build your program as a composition of functions, transforming data from $A$ to $B$, to $C$, etc., until the desired output is achieved. In object-oriented programming (OOP), you tell the computer what to do instruction by instruction. Functional programming is different: You give up the control flow and define a “recipe of functions” to produce your result instead.

FP originates from mathematics, specifically lambda calculus, a logic system of function abstraction. Instead of OOP concepts such as loops, classes, polymorphism, or inheritance, FP deals strictly in abstraction and higher-order functions, mathematical functions that accept other functions as input.
In a nutshell, FP has two major “players”: data (the model, or information required for your problem) and functions (representations of the behavior and transformations among data). By contrast, OOP classes explicitly tie a particular domain-specific data structure—and the values or state associated with each class instance—to behaviors (methods) that are intended to be used with it.
We will examine three key aspects of FP more closely:
- FP is declarative.
- FP uses function composition.
- FP functions are pure.
A good starting place to dive into the FP world further is Haskell, a strongly typed, purely functional language. I recommend the Learn You a Haskell for Great Good! interactive tutorial as a beneficial resource.
FP Ingredient #1: Declarative Programming
The first thing you’ll notice about an FP program is that it’s written in declarative, as opposed to imperative, style. In short, declarative programming tells a program what needs to be done instead of how to do it. Let’s ground this abstract definition with a concrete example of imperative versus declarative programming to solve the following problem: Given a list of names, return a list containing only the names with at least three vowels and with the vowels shown in uppercase letters.
Imperative Solution
First, let’s examine this problem’s imperative solution in Kotlin:
fun namesImperative(input: List<String>): List<String> {
val result = mutableListOf<String>()
val vowels = listOf('A', 'E', 'I', 'O', 'U','a', 'e', 'i', 'o', 'u')
for (name in input) { // loop 1
var vowelsCount = 0
for (char in name) { // loop 2
if (isVowel(char, vowels)) {
vowelsCount++
if (vowelsCount == 3) {
val uppercaseName = StringBuilder()
for (finalChar in name) { // loop 3
var transformedChar = finalChar
// ignore that the first letter might be uppercase
if (isVowel(finalChar, vowels)) {
transformedChar = finalChar.uppercaseChar()
}
uppercaseName.append(transformedChar)
}
result.add(uppercaseName.toString())
break
}
}
}
}
return result
}
fun isVowel(char: Char, vowels: List<Char>): Boolean {
return vowels.contains(char)
}
fun main() {
println(namesImperative(listOf("Iliyan", "Annabel", "Nicole", "John", "Anthony", "Ben", "Ken")))
// [IlIyAn, AnnAbEl, NIcOlE]
}
We will now analyze our imperative solution with a few key development factors in mind:
-
Most efficient: This solution has optimal memory usage and performs well in Big O analysis (based on a minimum number of comparisons). In this algorithm, it makes sense to analyze the number of comparisons between characters because that’s the predominant operation in our algorithm. Let $n$ be the number of names, and let $k$ be the average length of the names.
- Worst-case number of comparisons: $n(10k)(10k) = 100nk^2$
- Explanation: $n$ (loop 1) * $10k$ (for each character, we compare against 10 possible vowels) * $10k$ (we execute the
isVowel()check again to decide whether to uppercase the character—again, in the worst case, this compares against 10 vowels). - Result: Since the average name length won’t be more than 100 characters, we can say that our algorithm runs in $O(n)$ time.
- Complex with poor readability: Compared to the declarative solution we’ll consider next, this solution is much longer and harder to follow.
-
Error-prone: The code mutates the
result,vowelsCount, andtransformedChar; these state mutations can lead to subtle errors like forgetting to resetvowelsCountback to 0. The flow of execution may also become complicated, and it is easy to forget to add thebreakstatement in the third loop. - Poor maintainability: Since our code is complex and error-prone, refactoring or changing the behavior of this code may be difficult. For example, if the problem was modified to select names with three vowels and five consonants, we would have to introduce new variables and change the loops, leaving many opportunities for bugs.
Our example solution illustrates how complex imperative code might look, although you could improve the code by refactoring it into smaller functions.
Declarative Solution
Now that we understand what declarative programming isn’t, let’s unveil our declarative solution in Kotlin:
fun namesDeclarative(input: List<String>): List<String> = input.filter { name ->
name.count(::isVowel) >= 3
}.map { name ->
name.map { char ->
if (isVowel(char)) char.uppercaseChar() else char
}.joinToString("")
}
fun isVowel(char: Char): Boolean =
listOf('A', 'E', 'I', 'O', 'U', 'a', 'e', 'i', 'o', 'u').contains(char)
fun main() {
println(namesDeclarative(listOf("Iliyan", "Annabel", "Nicole", "John", "Anthony", "Ben", "Ken")))
// [IlIyAn, AnnAbEl, NIcOlE]
}
Using the same criteria that we used to evaluate our imperative solution, let’s see how the declarative code holds up:
-
Efficient: The imperative and declarative implementations both run in linear time, but the imperative one is a bit more efficient because I’ve used
name.count()here, which will continue to count vowels until the name’s end (even after finding three vowels). We can easily fix this problem by writing a simplehasThreeVowels(String): Booleanfunction. This solution uses the same algorithm as the imperative solution, so the same complexity analysis applies here: Our algorithm runs in $O(n)$ time. - Concise with good readability: The imperative solution is 44 lines with large indentation compared to our declarative solution’s length of 16 lines with small indentation. Lines and tabs aren’t everything, but it is evident from a glance at the two files that our declarative solution is much more readable.
-
Less error-prone: In this sample, everything is immutable. We transform a
List<String>of all names to aList<String>of names with three or more vowels and then transform eachStringword to aStringword with uppercase vowels. Overall, having no mutation, nested loops, or breaks and giving up the control flow makes the code simpler with less room for error. -
Good maintainability: You can easily refactor declarative code due to its readability and robustness. In our previous example (let’s say the problem was modified to select names with three vowels and five consonants), a simple solution would be to add the following statements in the
filtercondition:val vowels = name.count(::isVowel); vowels >= 3 && name.length - vowels >= 5.
As an added positive, our declarative solution is purely functional: Each function in this example is pure and has no side effects. (More about purity later.)
Bonus Declarative Solution
Let’s take a look at the declarative implementation of the same problem in a purely functional language like Haskell to demonstrate how it reads. If you’re unfamiliar with Haskell, note that the . operator in Haskell reads as “after.” For example, solution = map uppercaseVowels . filter hasThreeVowels translates to “map vowels to uppercase after filtering for the names that have three vowels.”
import Data.Char(toUpper)
namesSolution :: [String] -> [String]
namesSolution = map uppercaseVowels . filter hasThreeVowels
hasThreeVowels :: String -> Bool
hasThreeVowels s = count isVowel s >= 3
uppercaseVowels :: String -> String
uppercaseVowels = map uppercaseVowel
where
uppercaseVowel :: Char -> Char
uppercaseVowel c
| isVowel c = toUpper c
| otherwise = c
isVowel :: Char -> Bool
isVowel c = c `elem` vowels
vowels :: [Char]
vowels = ['A', 'E', 'I', 'O', 'U', 'a', 'e', 'i', 'o', 'u']
count :: (a -> Bool) -> [a] -> Int
count _ [] = 0
count pred (x:xs)
| pred x = 1 + count pred xs
| otherwise = count pred xs
main :: IO ()
main = print $ namesSolution ["Iliyan", "Annabel", "Nicole", "John", "Anthony", "Ben", "Ken"]
-- ["IlIyAn","AnnAbEl","NIcOlE"]
This solution performs similarly to our Kotlin declarative solution, with some additional benefits: It is readable, simple if you understand Haskell’s syntax, purely functional, and lazy.
Key Takeaways
Declarative programming is useful for both FP and Reactive Programming (which we will cover in a later section).
- It describes “what” you want to achieve—rather than “how” to achieve it, with the exact order of execution of statements.
- It abstracts a program’s control flow and instead focuses on the problem in terms of transformations (i.e., $A \rightarrow B \rightarrow C \rightarrow D$).
- It encourages less complex, more concise, and more readable code that is easier to refactor and change. If your Android code doesn’t read like a sentence, you’re probably doing something wrong.
If your Android code doesn't read like a sentence, you're probably doing something wrong.
Still, declarative programming has certain downsides. It is possible to end up with inefficient code that consumes more RAM and performs worse than an imperative implementation. Sorting, backpropagation (in machine learning), and other “mutating algorithms” aren’t a good fit for the immutable, declarative programming style.
FP Ingredient #2: Function Composition
Function composition is the mathematical concept at the heart of functional programming. If function $f$ accepts $A$ as its input and produces $B$ as its output ($f: A \rightarrow B$), and function $g$ accepts $B$ and produces $C$ ($g: B \rightarrow C$), then you can create a third function, $h$, that accepts $A$ and produces $C$ ($h: A \rightarrow C$). We can define this third function as the composition of $g$ with $f$, also notated as $g \circ f$ or $g(f())$:

Every imperative solution can be translated into a declarative one by decomposing the problem into smaller problems, solving them independently, and recomposing the smaller solutions into the final solution through function composition. Let’s look at our names problem from the previous section to see this concept in action. Our smaller problems from the imperative solution are:
-
isVowel :: Char -> Bool: Given aChar, return whether it’s a vowel or not (Bool). -
countVowels :: String -> Int: Given aString, return the number of vowels in it (Int). -
hasThreeVowels :: String -> Bool: Given aString, return whether it has at least three vowels (Bool). -
uppercaseVowels :: String -> String: Given aString, return a newStringwith uppercase vowels.
Our declarative solution, achieved through function composition, is map uppercaseVowels . filter hasThreeVowels.
![A top diagram has three blue "[String]" boxes connected by arrows pointing to the right. The first arrow is labeled "filter has3Vowels" and the second is labeled "map uppercaseVowels." Below, a second diagram has two blue boxes on the left, "Char" on top, and "String" below, pointing to a blue box on the right, "Bool." The arrow from "Char" to "Bool" is labeled "isVowel," and the arrow from "String" to "Bool" is labeled "has3Vowels." The "String" box also has an arrow pointing to itself labeled "uppercaseVowels."](https://bs-uploads.toptal.io/blackfish-uploads/public-files/image_2-05a7c998a806e858d12f8efc44d195a8.png)
This example is a bit more complicated than a simple $A \rightarrow B \rightarrow C$ formula, but it demonstrates the principle behind function composition.
Key Takeaways
Function composition is a simple yet powerful concept.
- It provides a strategy for solving complex problems in which problems are split into smaller, simpler steps and combined into one solution.
- It provides building blocks, allowing you to easily add, remove, or change parts of the final solution without worrying about breaking something.
- You can compose $g(f())$ if the output of $f$ matches the input type of $g$.
When composing functions, you can pass not only data but also functions as input to other functions—an example of higher-order functions.
FP Ingredient #3: Purity
There is one more key element to function composition that we must address: The functions you compose must be pure, another concept derived from mathematics. In math, all functions are computations that always yield the same output when called with the same input; this is the basis of purity.
Let’s look at a pseudocode example using math functions. Assume we have a function, makeEven, that doubles an integer input to make it even, and that our code executes the line makeEven(x) + x using the input x = 2. In math, this computation would always translate to a calculation of $2x + x = 3x = 3(2) = 6$ and is a pure function. However, this is not always true in programming—if the function makeEven(x) mutated x by doubling it before the code returned our result, then our line would calculate $2x + (2x) = 4x = 4(2) = 8$ and, even worse, the result would change with each makeEven call.
Let’s explore a few types of functions that are not pure but will help us define purity more specifically:
-
Partial functions: These are functions that are not defined for all input values, such as division. From a programming perspective, these are functions that throw an exception:
fun divide(a: Int, b: Int): Floatwill throw anArithmeticExceptionfor the inputb = 0caused by division by zero. -
Total functions: These functions are defined for all input values but can produce a different output or side effects when called with the same input. The Android world is full of total functions:
Log.d,LocalDateTime.now, andLocale.getDefaultare just a few examples.
With these definitions in mind, we can define pure functions as total functions with no side effects. Function compositions built using only pure functions produce more reliable, predictable, and testable code.
Tip: To make a total function pure, you can abstract its side effects by passing them as a higher-order function parameter. This way, you can easily test total functions by passing a mocked higher-order function. This example uses the @SideEffect annotation from a library we examine later in the tutorial, Ivy FRP:
suspend fun deadlinePassed(
deadline: LocalDate,
@SideEffect
currentDate: suspend () -> LocalDate
): Boolean = deadline.isAfter(currentDate())
Key Takeaways
Purity is the final ingredient required for the functional programming paradigm.
- Be careful with partial functions—they can crash your app.
- Composing total functions is not deterministic; it can produce unpredictable behavior.
- Whenever possible, write pure functions. You’ll benefit from increased code stability.
With our overview of functional programming completed, let’s examine the next component of future-proof Android code: reactive programming.
Reactive Programming 101
Reactive programming is a declarative programming pattern in which the program reacts to data or event changes instead of requesting information about changes.
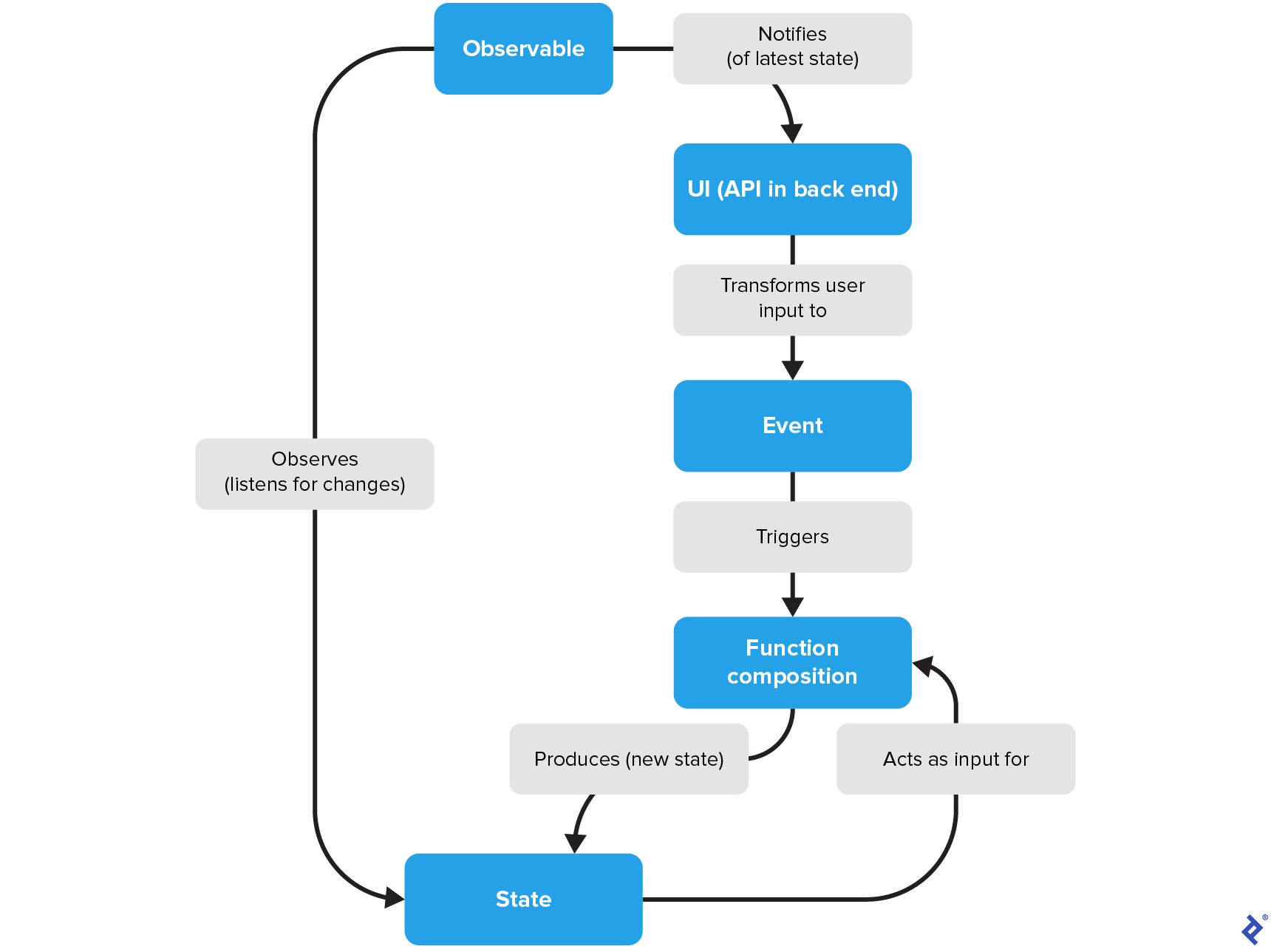
The basic elements in a reactive programming cycle are events, the declarative pipeline, states, and observables:
- Events are signals from the outside world, typically in the form of user input or system events, that trigger updates. The purpose of an event is to transform a signal into pipeline input.
- The declarative pipeline is a function composition that accepts
(Event, State)as input and transforms this input into a newState(the output):(Event, State) -> f -> g -> … -> n -> State. Pipelines must perform asynchronously to handle multiple events without blocking other pipelines or waiting for them to finish. - States are the data model’s representation of the software application at a given point in time. The domain logic uses the state to compute the desired next state and make corresponding updates.
-
Observables listen for state changes and update subscribers on those changes. In Android, observables are typically implemented using
Flow,LiveData, orRxJava, and they notify the UI of state updates so it can react accordingly.
There are many definitions and implementations of reactive programming. Here, I have taken a pragmatic approach focused on applying these concepts to real projects.
Connecting the Dots: Functional Reactive Programming
Functional and reactive programming are two powerful paradigms. These concepts reach beyond the short-lived lifespan of libraries and APIs, and will enhance your programming skills for years to come.
Moreover, the power of FP and reactive programming multiplies when combined. Now that we have clear definitions of functional and reactive programming, we can put the pieces together. In part 2 of this tutorial, we define the functional reactive programming (FRP) paradigm, and put it into practice with a sample app implementation and relevant Android libraries.
The Toptal Engineering Blog extends its gratitude to Tarun Goyal for reviewing the code samples presented in this article.
Further Reading on the Toptal Engineering Blog:
Understanding the basics
The heart of functional programming is function composition, in which data is transformed from A to B, to C, to the desired output. It also has two other key elements: It is declarative, and its functions are pure.
Reactive programming is a programming pattern rooted in two concepts: declarative programming and reactivity.
Reactive programs respond directly to data or event changes instead of requesting information about changes.
Comments